【精】如何在项目中开启上帝视角——由浅入深研究监控系统
监控系统俗称“第三只眼”,几乎是我们每天都会打交道的系统。本文将会从一个简单的监控系统开始,讲解系统模块组成,监控数据流向,由浅入深,研究典型监控系统的设计,最后比较一下两个监控系统的架构设计和场景表现。由于作者本人也是刚入门的新手,文章中如有错漏,欢迎随时指正。
监控系统的工作原理
关于监控系统信息的分类,目前还没有比较统一的说法。本文将监控信息分为三类:基本信息、主机(容器)资源信息和应用(服务)信息,上述三种分类刚好对应了三类具有不同特点的信息:
| 分类 | 特点 | 举例 |
|---|---|---|
| 基本信息 | 由计算机本身确定、长期不变、通常只需要采集一次 | CPU频率、内存大小、磁盘空间、网络地址等 |
| 主机(容器)资源信息 | 随时改变、客观存在、用户不可定义和修改 | CPU利用率、内存利用率、磁盘利用率、网络传输速率等 |
| 应用(服务)信息 | 类型多样、用户可自定义和修改、每台主机都不一样 | 服务技术栈,metrics信息 |
Prometheus对于Metrics的定义如下:
Metrics are numerical measurements in layperson terms. The term time series refers to the recording of changes over time.
……
For a web server, it could be request times; for a database, it could be the number of active connections or active queries, and so on.
简单来说,metrics就是一系列随着时间改变的测量数据。可以是接口请求次数,也可以是数据库的连接次数。
监控系统基本框架
下面是一个简单的监控系统(PiMonitor)整体架构图,包含四个模块:
- PiMetric模块用于采集和导出指标监控信息。
- Agent部署在用户的计算机上,用于获取计算机的基本信息、资源利用率、和本机所有服务指标监控信息。
- Server模块负责存储和查询数据,和Agent、Web两端交互。
- Web模块负责数据的展示。
这一部分内容将会以PiMonitor监控系统为例,聚焦于Agent模块、PiMetric模块和数据层(主要是时序数据库InfluxDB),讲述监控系统的工作原理。其他次要模块(帐号系统、团队系统和Web展示模块)不会多做介绍。
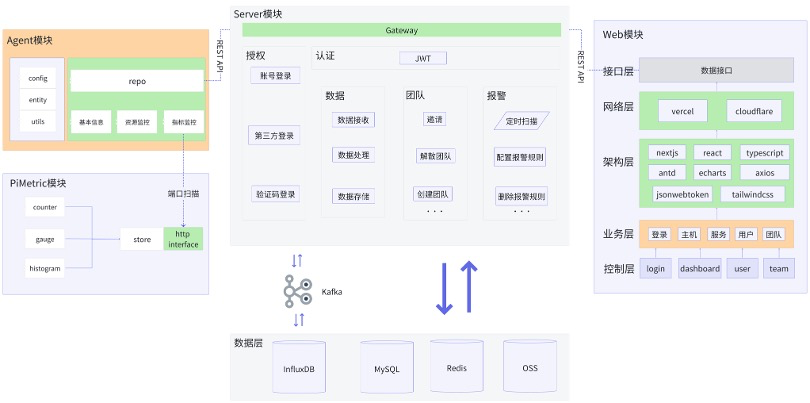
上述架构图源于我的一个课程设计,麻雀虽小五脏俱全,它省略了抓取池、注册表等概念,简化了Metric设计,用最简单的例子说明监控系统的工作原理。有相关基础的读者可以选择性跳过部分内容。
感兴趣话可以看看这里:https://github.com/Veni222987/PiMonitor
监控信息从哪里来
监控信息的获取主要有两大类的方法:非侵入式和侵入式的。非侵入式是指不在业务逻辑中写监控信息记录有关的代码,例如获取内存大小和利用率这类信息只需要调用系统接口获取即可。而侵入式是指需要在业务逻辑中写监控代码,例如统计某个接口的调用次数,通常的做法是在调用接口的时候对计数器进行自增操作。接下来我们看看上述三种分类信息是如何获取的。
基本信息和主机(容器)资源信息主要是使用系统提供的接口获取的,当然也可以使用第三方工具(如psutil获取)。例如,使用gopsutil可以获取系统的基本信息和资源信息。
gopsutil (go process and system utilities): Go语言主流的系统与进程信息获取工具,目前GitHub上已有10k+ stars。
GitHub地址:https://github.com/shirou/gopsutil
在引入了gopsutil的mem模块之后,获取计算机内存总量的代码十分简洁:
1 | func getMemory() (uint64, error) { |
获取内存利用率的代码也类似:
1 | // 获取内存使用率 |
可以观察到,获取内存总量和获取内存利用率实际上都是由mem包的VirtualMemory获取的,但是在我们自己搭建监控系统的时候,一定不想把CPU型号、核数、频率等长期不变的数据每一次都上传一份重复的信息。因此,通常的设计是计算机运行一个agent,由这个agent分开获取不同类型的数据,计算机信息单独获取并且调用对应的接口获取一次,资源利用率、应用(服务)监控等信息由一个单独的协程持续获取并且上传。
应用(服务)信息获取一般都是侵入式的,简单来说,就是当我们想要在某个一业务中往监控系统中记录信息的时候,这里必须要写一些和监控系统操作相关的代码。例如:想要获取某一个接口的调用次数,就需要在调用接口之后对计数器进行自增操作:
1 | // 调用接口传出去 |
总结一下监控信息从哪里来这个问题:
- 对于由计算机本身确定的信息,无论是基本信息还是资源信息,都可以通过gopsutil这类工具直接从系统获取。其中基本信息可以一次性获取,资源利用率信息需要一个单独的协程持续获取。
- 对于应用(服务)的信息,通常是需要在代码中侵入式地接入对应的监控系统模块,埋点记录监控指标对应的值,然后持续获取、存储和上传。
根据上面的描述,作出时序图如下:
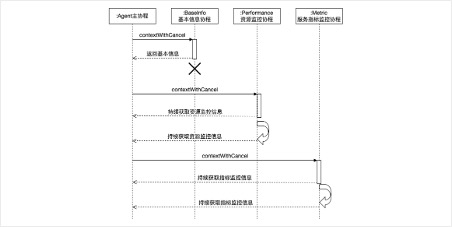
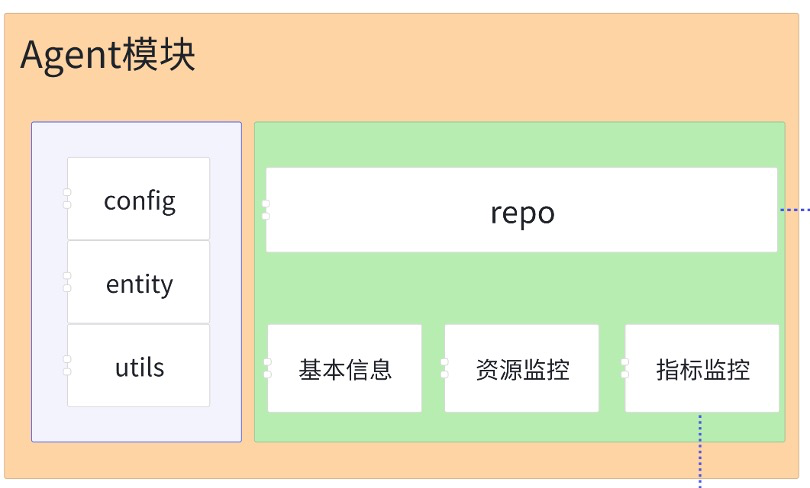
这个时候再回头看看上面的监控系统架构图中的Agent模块,基本信息、资源监控、指标监控三个子模块应该就好理解多了。左侧的是辅助包,顶部repo用于上传数据到服务端,剩下的三个子模块就是获取三类不同监控信息的模块。
监控信息如何导出和传输
上面说完了监控信息是如何获取的,接下来我们看一下监控信息是如何导出的。还是以上面提到的pimetric为例,理解一下监控信息如何从应用到agent。
当监控系统获取到监控信息的时候,就需要先把信息展示保存起来。最简单的方式就是直接在内存中保存起来,当数据导出的时候再清理并释放内存。在pimetric中,我采用了最简单直接的方法:使用map保存不同类型的metric数据。
当我们可以保存和获取监控数据之后,下一步就可以考虑如何把这些监控数据导出给用户。通常的做法是:在服务中引用这个模块,对外提供监控数据,通过一个agent收集本机的数据并且通过push或pull的形式上传到服务器作持久化存储(下面会讲)。这里先看一下数据是如何导出的。
在pimetric中,主要有两种方式导出数据:
- 只导出一个handler,由服务自行注册到对应的监听端口上,通常适用于http服务。下面的代码片段展示了如何生成一个handler并且在项目中使用。
1 | // GenHandler 指定appName生成handler,可以绑定到已有端口的特定路由上 |
- 监听新端口导出数据,适用于不开放http端口的服务,例如RPC服务、消费者服务等等。
1 | // ExportMetrics 监听新端口导出数据 |
当这些信息全部都可以通过本地接口调用获取的时候,Agent就会扫描本机的端口,获取本机所有监控信息。这样用户侧的工作基本完成了,这时候再回顾上文的架构图中用户侧的两个模块,基本上就能理解Agent模块和PiMetric模块是如何协调工作的了。
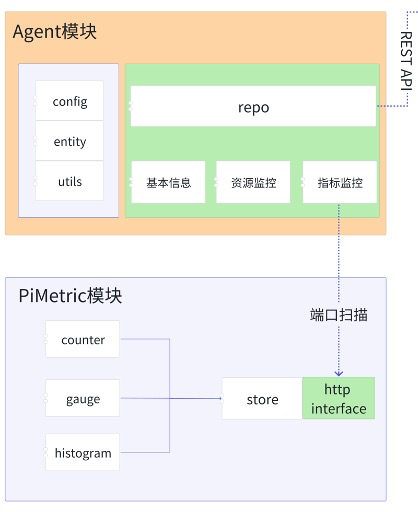
监控信息如何持久化存储
上面的局部图中有一个REST API,这个API就是用来做监控信息持久化存储的。Agent采用主动push的方式,每隔一段时间就会向监控系统服务器推送本机的所有监控数据。服务端收到上传的数据之后,经过Agent注册信息等检测,就会将数据写到Kafka中,再由Kafka消费者写入InfluxDB。
InfluxDB是一个时序数据库,它采用了一种时间序列数据模型,这意味着它特别适合存储与时间有关的数据。要理解InfluxDB需要理解几个比较关键的概念:
measurement:一组测量数据,相当于SQL中的一张表。
point:一个数据记录点,相当于SQL中的一行数据。
field:测量值,一般而言是数据,没有索引,不可以根据field查找。
tag:标签,可以理解成为SQL中带有索引的列,可以根据tag快速查找。
与SQL不同的是,InfluxDB不需要预先定义measurement,而是在插入数据的时候自动处理field,这就是“时间就是一切”的思想,文档中有这样一句话:
InfluxDB还会认识到您的schema可能随时间而改变。在InfluxDB中,您不需要在前面定义schema。数据点可以有一个measurement的field的一个,也可以有这个measurement的所有field,或其间的任何数字。 您可以在写数据的时候为该measurement添加一个新的field。
理解了上述几个概念之后,我们可以制定三类数据的持久化存储方式:
| 数据类型 | 存储模块 | 存储方式设计 |
|---|---|---|
| 计算机基本信息 | MySQL | 一个agent对应记录一行数据,包括CPU型号、频率、内存、磁盘等字段 |
| 资源利用率信息 | InfluxDB | 一台agent对应一个measurement,fields是CPU利用率,内存利用率等信息,每次push上传一次数据作为一个point |
| 应用(服务)信息 | InfluxDB | 一台agent对应一个measurement,使用tag区分不同的服务,fields是不同的服务对应的metrics。 |
例如,Metric在InfluxDB中存储的形式是这样的:
1 | name: agent1_metrics |
小结
这一部分主要以一个简单的监控系统(PiMonitor)入手,逐步解析了监控系统的模块设计和数据结构,能看懂上面的四个小节基本上就能理解监控系统的工作原理了。接下来将会研究一下目前主流的监控系统Prometheus设计。
Prometheus设计研究
现在最主流的监控系统应该就是Promethues+Grafana搭建的监控系统了。其中Promethues负责数据采集与存储,Grafana负责数据的展示。下面我们将会深入看一下这一套监控系统的设计细节。首先看看Prometheus的架构图:
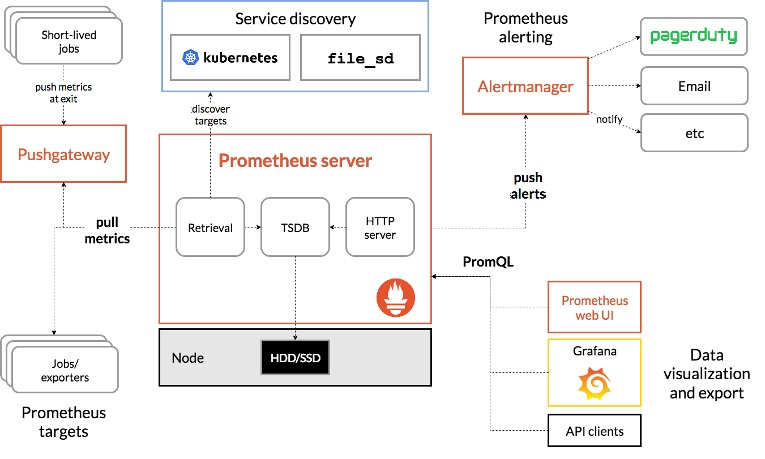
数据传输方式设计
Prometheus提供了两种数据传输的方式:分别是pull模式和push模式。这里主要讲讲pull模式是如何工作的。
Prometehus使用了一个target类型的结构记录一个监控节点,target类型的结构包括节点的标签、上次拉取时间、Metric元数据等等:
1 | // Target refers to a singular HTTP or HTTPS endpoint. |
除了target,Prometehus的数据拉取模块还有几个关键的结构:
- Manager: 负责管理所有抓取任务和target集合的更新,包括加载配置,启动和停止循环等。Manager根据配置文件创建scrapePool,然后交给scrapePool负责具体的抓取工作,期间可能会执行Sync同步配置文件的target更新。
- scrapePool: 管理一组目标抓取任务,通常对应一个抓取配置分组。scrapePool为targetGroup下的每个target,创建1个scrapeLoop,然后让scrapeLoop抓取数据。
- scrapeLoop: 负责定期从target中抓取监控数据,包括scrape抓取数据,append写入存储模块等等。
用户通过一个yaml配置文件管理一个Manager,Manager依次往下管理scrapePool,scrapeLoop,最后把请求发到target。不同的Loop使用不同的协程独立获取target信息,确保了系统的高效性和稳定性。下面的示意图可以很清楚地展示服务端拉取数据的工作流程:
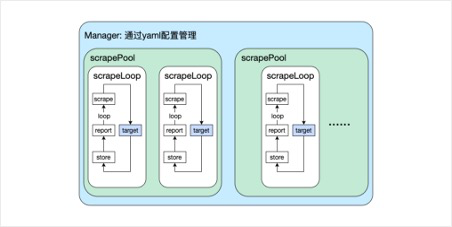
Prometheus的服务端仓库的地址:https://github.com/prometheus/prometheus
Prometheus对不同的语言提供了不同的客户端,go语言版本的仓库地址:https://github.com/prometheus/client_golang
看完了server侧的拉取原理,接下来看看client侧的工作原理。同样的,先介绍一下client侧几个重要的概念:
- Registry:用于注册和管理所有的指标。可以使用默认的全局注册表,也可以创建自定义注册表,注册表是指标数据的集合体。
- Collector:表示可以被 Prometheus 收集的指标,包括Describe和Collect函数,Registry 实现了Collector接口。client_golang内置了一些Collector,例如GoCollector,ProcessCollector等。
- Gatherer****:用于收集所有注册的指标。Registry 实现了 Gatherer 接口,包含一个Gather函数,该函数返回一个MetricFamily结构体,包含各种类型的Metric信息,结构体定义可以自行到源码中查看。
client_golang中,监听HTTP端口并且暴露metrics端点的代码如下,reg是一个Registry注册表,当用户发送一个HTTP GET请求到 *ip:port/metrics* 的时候,请求的返回结果就是这个注册表中的Metrics。
1 | m := http.NewServeMux() |
至此,client侧的工作原理也基本清楚了,整理得出client侧工作流程图如下,最终形成的target就是上文中服务侧scrapeLoop需要调用的target。
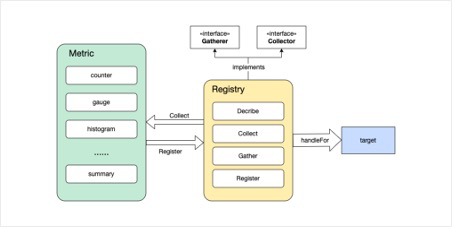
由于暂时没有深入研究prometheus的push模式源码,这里只做简单的描述,prometheus的push模式实现方法是:对于一些短作业,把监控数据push到一个专门的gateway,再由服务器从这个gateway拉取数据。感兴趣的读者也可以自己阅读学习一下。
Metric类型设计
从宏观角度看,所有的metric都包含一个对外导出的接口,以及一个实现该接口的结构体。这里挑了三个最具代表性的类型详细研究一下,分别是:counter, gauge和histogram。
Counter
counter是一种只能上升的指标,通常用于记录接口的请求次数,失败次数等。因此,Counter接口只包含了两个自定义函数:Inc和Add。Counter类型的接口还继承了Metric接口和Collector接口,Metric接口用于获取Metric的描述等信息。
1 | type Counter interface { |
下面是Counter接口的实现结构,有几个值得关注的地方:
- 为什么有两个val值?而且均使用了uint64结构?
valBits代表一个float64的比特位,valInt代表一个精确的整数,两者均用uint64表示是为了在原子操作中保持一致。
- selfCollector是什么?有什么作用?
counter并没有直接实现Collector接口,而是由selfCollector实现了Collector接口,selfCollector是一个与Metric无关的结构体,在其他Metric中也存在,这样的设计简化了代码。
- exemplar是什么?
exemplar是一个基于原子量进行读写的结构,可以为metrics添加trace信息,这样metrics和tracing就可以关联起来。不过我认为,Prometheus对于trace的支持不是很好,这一部分可以去看看其他的监控系统。
1 | type counter struct { |
Gauge
gauge类型的接口设计如下,同样继承了Metric和Collector两个接口,并且定义了一些gauge类型独有的操作。
1 | type Gauge interface { |
gauge类型的结构体定义如下,valBits也是使用unit64记录的float64值,相比于counter,gauge结构体少了valInt,exemplar等,因为gauge本身的定义就是一系列随时间变化的测量数据,绝大多数情况下是非整形的,所以只需要一个float64类型的数据即可。
1 | type gauge struct { |
Histogram
histogram相当于统计数据,一般适用于记录一些能够做成统计直方图的数据。histogram类型同样继承了Metric和Collector接口,并且只包含一个Observe函数,该函数用于将一个观测值加入到histogram统计数据中。
1 | type Histogram interface { |
histogram的结构体比较复杂,包含的数据结构很多,重点关注一下countAndHotIdx, counts, upperBounds这几个与数据存储紧密相关的字段下面主要讲histogram类型的数据存储的实现。
1 | type histogram struct { |
我们将从它唯一的Observe函数入手,研究一下数据的存储方式。首先我们假定已经定义好了存储桶bucket,存储桶是一系列的用于分隔数据范围的浮点数,例如默认的存储桶为:
1 | var DefBuckets = []float64{.005, .01, .025, .05, .1, .25, .5, 1, 2.5, 5, 10} |
然后观察Observe函数的实现,Observe函数接受唯一的float64类型输入,表示一个观测值,findBucket函数用于查找当前的观测值位于哪一个存储桶中:
1 | func (h *histogram) Observe(v float64) { |
获取存储桶的序号之后,就会调用一个内部函数observe,该函数的实现如下,n是一个原子自增的计数器,后面的右移63位表示只根据最高位取出热桶(热桶只有两个,可以看上面的结构体定义中的counts字段),然后调用该热桶的observe方法。doSparse是判断是否使用稀疏桶的布尔值,用于处理一些边界数据。
1 | // observe is the implementation for Observe without the findBucket part. |
最终的存储单位是histogramCounts的buckets,这个切片记录了每一个bucket区间内的数据总量。histogram并不保存原始数据,只关心数据的分布状况,因此会产生一定程度的信息丢失。如果在展示中出现的有关histogram的统计数值,一般是使用数学模型拟合出来的,与原始数据存在误差。
1 | func (hc *histogramCounts) observe(v float64, bucket int, doSparse bool) { |
这一部分介绍了三种主要的Metric的设计,总的来说还是有许多值得参考学习的地方的。其他Metric和一些具体细节也可以自己到client_golang源码中查看。
TSDB与PromQL
Prometheus有一个专用的时间序列数据库,位于prometheus/tsdb目录下,此外,他还提供了一种针对这个时序数据库的查询语言,称为PromQL,位于prometheus/promql目录下。由于上一部分中已经介绍过了InfluxDB,并且这两部分的源代码比较复杂,这里就简单介绍一下TSDB和PromQL的特性和功能。
在TSDB中,时间序列中的每一个点称为一个样本(sample),样本由以下三部分组成:
- 指标(metric):metric name和描述当前样本特征的labelsets;
- 时间戳(timestamp):毫秒级时间戳;
- 样本值(value): 一个float64的浮点型数据表示当前样本的值。
例如:
1 | <--------------- metric ---------------------><-timestamp -><-value-> |
由于prometheus的TSDB是专门为它自己服务的,所以整体设计上会比InfluxDB要简单一些。它使用了Metric代替InfluxDB的measurement的概念,原生支持记录Metric的时间序列记录,减少了自己转换结构和设计数据字段的工作。
当数据存入TSDB之后,就可以使用PromQL查询某个Metric数据。这里有两个关键的概念:
- Engine: 负责管理多次查询的整个生命周期,可以配置超时时间、日志等。
- Query: 是一个接口,负责管理一次查询,包括查询语句、执行、取消、关闭等操作。
本质上,PromQL(Prometheus Query Language)就是一个针对TSDB的QL,其功能和用法都类似SQL,一般而言在搭建可视化平台的时候就写好的,后期改动较少,这里就不加赘述了。
架构差异与功能比较
上文介绍了两个监控系统:PiMonitor和Prometheus,两者的架构设计最大的区别在于是否有单独Agent代理,这个区别导致了某些场景下两个监控系统有不同的表现:
| 功能 | PiMonitor | Prometheus |
|---|---|---|
| 计算机信息采集 | 原生支持采集计算机基本信息和资源利用率 | 需要启动额外的Exporter |
| 服务与框架集成 | 需要在服务中手动指定所有监控指标 | 许多服务和框架都预留了Prometheus监控集成功能 |
| 信息传输方式 | 仅支持通过Agent上传的push模式 | 以pull模式为主,push模式为辅 |
| 新增服务 | 可以监控所有使用pimetric模块的服务,启动后无需额外操作 | 每次增加新服务都需要修改服务端拉取目标的配置文件 |
总结
本文由浅入深,从自己的监控系统入手,讲述了监控系统的基本组成部分和数据流向,让读者对于监控系统的工作原理有了基本的认识。然后研究了社区最活跃的监控系统Prometheus,学习其架构设计和底层实现,尽管只研究了冰山一角,但也让人获益匪浅。
本文也有一定的局限性,由于Prometheus是一个以Metric为核心的监控系统,对于日志(Log)、调用链(Trace)的支持不佳,难以打造一个全方位的监控系统,这篇文章也因此缺少了这两部分可观测对象监控的工作原理。
感谢大家的阅读,如有错误,欢迎指出。
参考资料
Prometheus官方文档:https://prometheus.io/docs/introduction/overview/
InfluxDB中文文档:https://jasper-zhang1.gitbooks.io/influxdb/content/
技术文章: