Java内置集合框架及其线程安全性
首先需要了解一下Java的集合框架,主要包含三部分:Collection, Iterator和Map。Collection是集合,包括List, Set, Queue等等。Iterator是迭代器,Map是映射。本文不会讲解他们的基本使用和常用方法,主要针对特性和彼此的异同进行研究。我们先来看一下Java的集合框架的总览图:

这里面的数据结构非常多,一开始可能会一无所措,但是其实慢慢拆解发现也没那么难。
Collection
Colletion是最常用的集合工具,下面这张图表现了Collection中的主要接口和类及其特点。
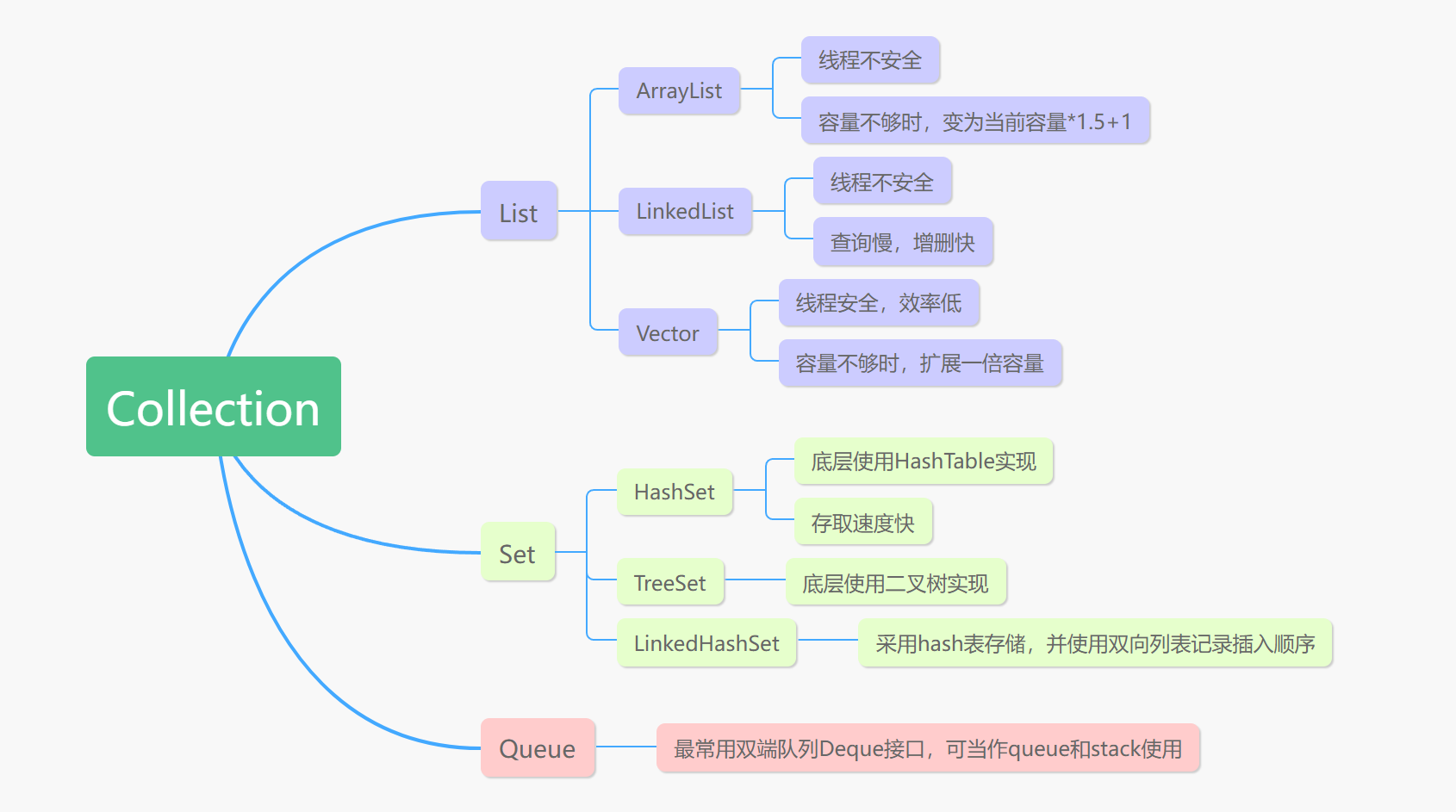
Collection Interface
先来看一下Collection接口的源码都有哪些函数吧。
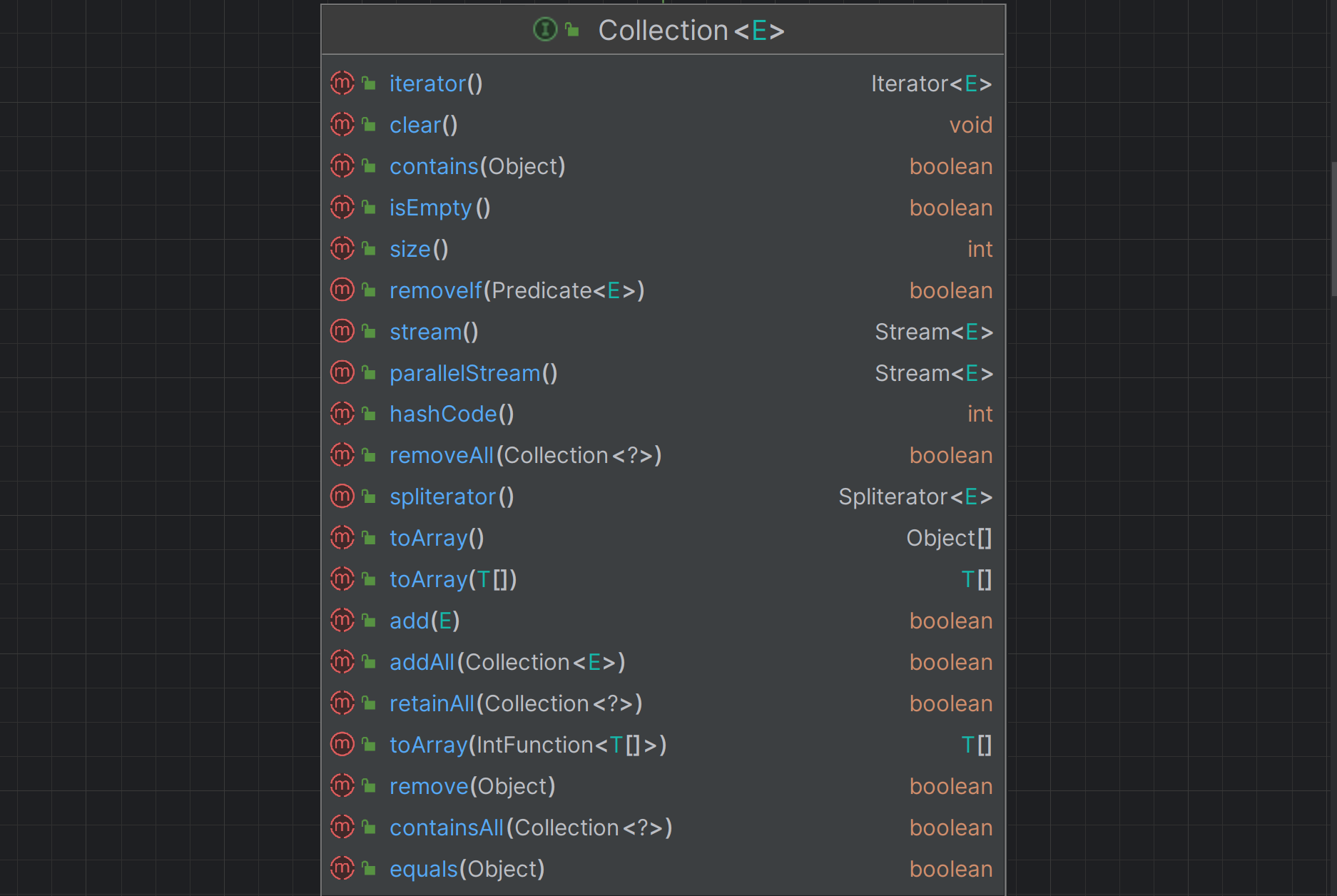
不难发现,Collection的这些操作都是集合的常见操作,尤其是contains, clear, add, remove等等。这些接口在不同的数据结构中有不同的实现,例如对于一个List而言,remove就是直接移除队首元素,而对于一个堆(或者说优先队列)而言,remove就是移除堆顶元素,然后将最后一个元素放上来往下筛。
List
先说List。从实现方式上面看,ArrayList和Vector是基于数组的,这两者比较相似,而LinkedList是基于链表的。但是从线程安全性看,Vector又是相对于ArrayList和LinkedList更独特的。Vector的函数中使用了synchronized关键字,例如下面的addElement函数。synchronized关键字确保了在多线程的情况下,Vector的方法是同步的,同一时间只能有一个线程访问Vector的方法。
1 | public synchronized void addElement(E obj) { |
下面我们将写一段代码验证一下Vector的线程安全。首先写一个线程类,实现Runnable接口,并且重写run()函数。构造函数传入一个List。注意List是一个接口,可以实例化为ArrayList,LinkedList和Vector。
1 | static class ListThread implements Runnable { |
接下来我们会创建一个共享的List变量,然后实例化两个线程并将List传进去,每个线程往List中加入10000个元素(这个动作是由上面的run函数决定的,也可以测试其他的函数)。
1 | public static void main(String[] args) { |
如果List是实例化为Vector的话,那么最终的sharedList.size始终是20000的,但是实例化为ArrayList和LinkedList则基本上不可能达到20000。
测试线程安全性的一般步骤是:创建共享对象->写一个线程类并传入共享对象->创建多个线程调用对象方法->观察结果。
Set
回到上面的图,常用的Set包括HashSet,TreeSet和LinkedHashSet。很遗憾,这三者都是非线程安全的,后面会讲如何在多线程中安全地使用Set。
HashSet基于哈希表实现,其增加、查找和删除元素都是O(1)的,并且允许存储null元素。LinkedHashSet是在HashSet的基础上添加了链表实现,使得迭代器迭代顺序和插入顺序一致。而TreeSet是基于红黑树实现的,时间复杂度是O(logn),不允许存储null元素。
- HashSet是如何保证元素的唯一性的
使用HashSet存储自定义的类时,一般都要重写hashCode()函数和equals(Object obj)函数。
先写一个自定义的Person类:
1 | class Person { |
然后new三个对象,其中两个的字段完全一样,将其加入set中:
1 | public static void main(String[] args) { |
观察结果,如果重写了equals方法和hashcode方法,那么size将会是2。任何一个没有重写都会是3。
在Java中,equals和hashCode应该是一致的,即equals为true的对象,其hashcode也应该为true。默认情况下,equals比较的是内存地址,而hashCode则是根据地址算出来的一个数。所以上面的例子中不重写的情况下,size为3。
- TreeSet是如何保证元素的唯一性的
TreeSet是基于红黑树的有序集合,它在插入元素时会根据元素的排序规则进行插入,从而保证元素的有序性。使用TreeSet存储自定义的类,也是需要满足一定的规范。在定义类的时候,需要实现Comparable<E>接口,重写compareTo函数,例如一个Person类根据年龄比较大小。
Queue
队列的使用其实比较简单,在Java中一般使用双端队列Deque,Deque实现了Queue的接口,而LinkedList实现了Deque的接口,所以Deque一般都实例化为LinkedList。注意几对操作:push和pop可以当作stack使用;add和remove,offer和poll可以当作queue使用,后面两组queue操作的区别在于返回类型,remove会抛出错误,而poll会返回布尔值。
Collections工具
Java.utils中Collections类包含许多常用的静态工具函数,例如对于List的reverse和sort等等。
上面我们提到的Set都是非线程安全的,那么想要使用线程安全的Set怎么办呢?那就可以用到Collections里面的synchronizedSet将普通的Set升级为线程安全的Set:
1 | // 创建一个普通的Set |
无论运行多少次输出size为1000(因为Set过滤相同元素),表明在多线程中确实所有修改都是同步的。
Map
讲完了Collection,下面讲讲Map。还是一张图大概了解一下Map家族。
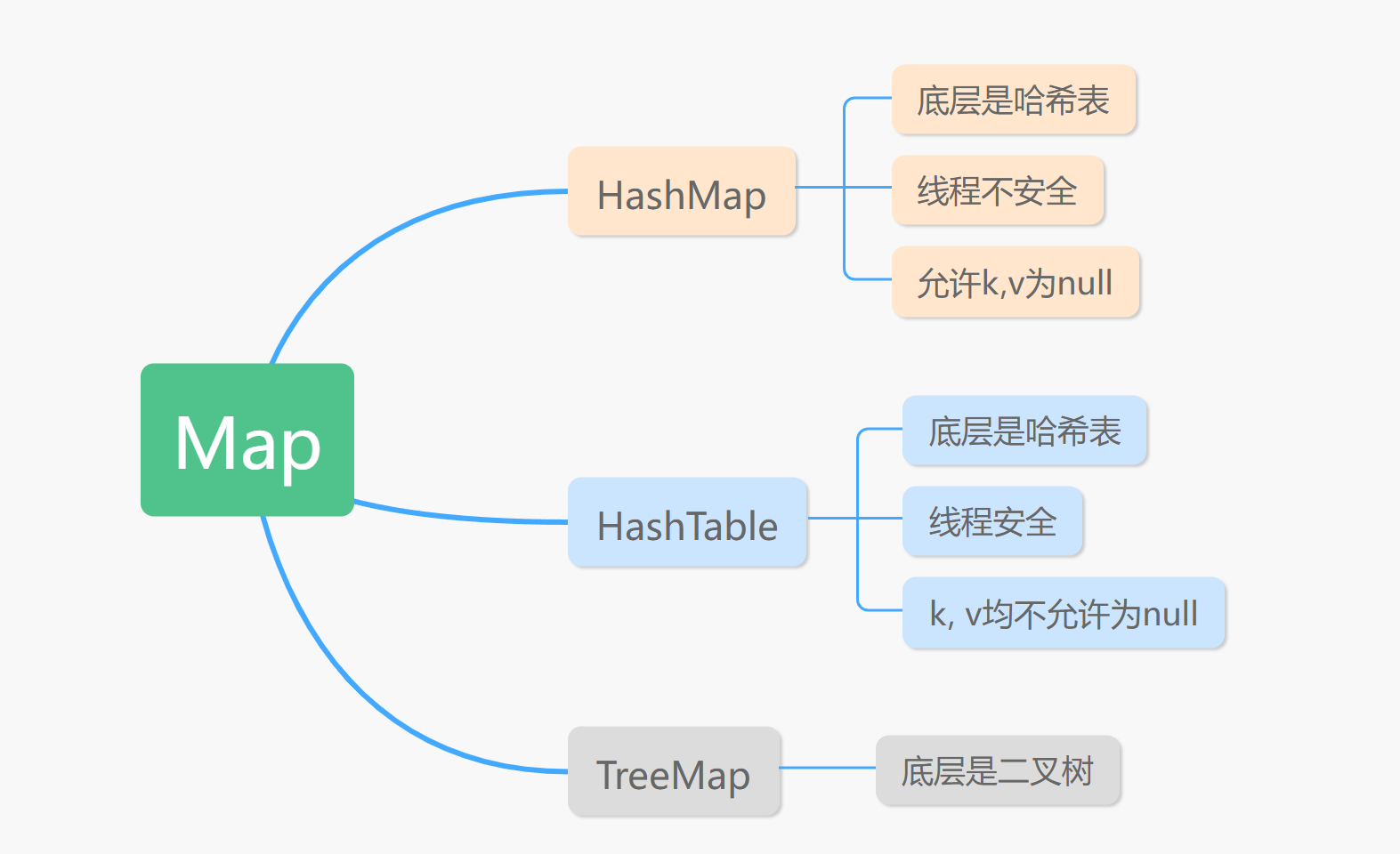
HashMap比HashTable单机性能要好,但是牺牲了线程安全性。Collections.synchronizedMap也可以将HashMap升级为线程安全的,用法和HashSet一样。
HashMap使用开哈希实现,同位置可以存储多个元素,最初使用链表的形式,在Java8中添加了红黑树,当链表中元素超过8个以后,同一位置的查找速度从O(n)变为O(logn)。
ConcurrentHashMap则弥补了HashMap的缺点,它使用了一个Segment数组来对HashMap实现加锁,从而保证了线程安全,因为分段加锁,也不会牺牲太多的速度。用法如下,直接new实例化即可:
1 | import java.util.Map; |
TreeMap是可排序的,和TreeSet类似,都需要实现Comparable接口。当使用Iterator遍历TreeMap的时候,得到的记录是排过序的。
Iterator
迭代器(Iterator)是一个接口,提供了一套遍历集合(这里的集合是广义集合,包括List, Set和Map)元素的方法。遍历List或许是一件比较简单的事情,但是遍历Set和Map则不然。所以迭代器就是在这样的需求下出现的。
通过调用集合对象的iterator()方法,可以获取到一个实现了Iterator接口的迭代器对象。主要操作包括hasNext和Next。
以ArrayList为例,其内部包括了一个私有类并且实现了迭代器接口,这里面的逻辑代码可以不必深究,知道迭代器实现的整体框架即可。
1 | private class Itr implements Iterator<E> { |
在调用iterator的时候,会new一个Itr并且返回:
1 | public Iterator<E> iterator() { |
注意到代码中迭代器可能会抛出两个异常:ConcurrentModificationException和NoSuchElementException。后者容易理解,每次调用next之前用hasNext判断即可。那么ConcurrentModificationException是什么意思呢?这是为了保证在多线程环境下的安全性。expectedModCount就是预期修改的次数,在多线程中,如果一个迭代器正在迭代,此时另一个线程对集合进行了修改,那么就会抛出这个异常。尽管设计是防止多线程的不一致性,在实际应用中,单线程情况下也会出现这个异常,那就是在迭代器迭代的时候修改了集合,例如remove,这样也是不允许的。
1 | while (iterator.hasNext()) { |
在某些场景需要对List从后往前遍历,并可能删除元素的情况下,不能使用迭代器遍历。
总结
本文总结了Java的集合框架的分类和特点。Java迭代至今,每一个类都是有存在的理由的。根据不同的场景使用不同的集合类,可以避免很多隐藏的错误,或者提升程序的运行效率。
